C言語やC++では、汎整数型のサイズは最小表現範囲と相対的な大小関係が決まっているだけで、それ以外は処理系定義になります。char型は少なくとも8ビット以上あれば何ビットでもよく、char型のサイズが1バイトということになります。int型も16ビット以上であれば何ビットでもかまいません。このことから、char型とint型のサイズがともに16ビットとか64ビットとかでもまったくかまわないということになります。
理屈の上ではわかっていても、具体的な処理系と関わることがなければ実感がわいてきません。ここでは、実際にchar型とint型のサイズが同じ処理系として、テキサス・インスツルメンツ社製のTMS320C28x Optimizing C/C++ Compilerをご紹介しましょう。このマニュアルの6.3 Data Typeを見ると次のような表が掲載されています。
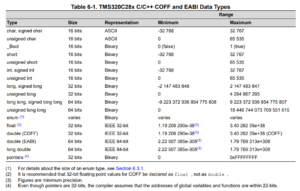
この表を見ると、char, signed char, unsigned charはすべて16ビットであり、int, signed int, unsigned intもすべて16ビットであることがわかります。まさにchar型とint型のサイズが同じ処理系です。このドキュメントは、当記事執筆時点(2021年6月27日)で2021年5月21日の日付になっており、決して過去の遺物ではないことがわかります。
というわけで、char型とint型のサイズが同じ処理系が実在することを確認できたので、今回はそういった処理系で起こるさまざまな奇妙な現象について考えてみることにします。
char型とint型のサイズが同じということは、unsigned char型、そしてchar型が符号付きの場合はchar型の表現範囲をint型が網羅していないことになります。その結果、char型が符号無しの場合であっても文字定数はint型でなければなりませんので、char型であれば正の値であっても文字定数では負の値になることがあります。直接比較した場合には、通常の算術型変換によってunsigned int型にそろえられるため大きな問題はなさそうです。しかし、いったんlong型にキャストして比較する場合には問題が生じます。
また、isalpha関数の引数はunsigned charの表現範囲かEOFでなければなりませんが、仮引数がint型なので仕様が破綻しています。fputc関数やungetc関数についても同様です。
fgetc関数(getc関数やgetchar関数も同様)については、EOFか文字を返すということなので、限りなく黒に近いグレーということになります。これらの関数は、ファイルの終端に達したときやエラーが発生したときはEOFを返すことになっていますが、正しい値かEOFなのかを判別する手段がありません。対策としては、返却値に依存するのではなく、feof関数やferror関数を使う必要がありそうです。
このような、char型とint型のサイズが同じ処理系への移植性を考慮して実装するのは、決して容易なことではありません。本当に必要な場合を除き、そうした処理系と対象外とするような「処理系の仮定」を行った上で設計する方が現実的ではないでしょうか?


![[迷信] 一重引用符の中には一文字しか書けない](https://www.kijineko.co.jp/wp-content/uploads/2021/06/4842077_s.jpg)

![[迷信] 今どきint型が16ビットの処理系なんて無い](https://www.kijineko.co.jp/wp-content/uploads/2021/05/4618601_s.jpg)